Transcript of my EuRuKo 2018 Talk
This is a very rough transcript of my talk, Metaprogramming for Generalists, given at this year’s EuRuKo conference in Vienna, Austria. There is also a video of the talk on YouTube.
Hi everybody, my name is Chris Salzberg and the title of this talk is “Metaprogramming for Generalists”. I know I know, you’re thinking, "He’s starting the morning of the first day with metaprogramming?!”
But don’t worry! This will be interesting.

About Me
Ok, so first about me. My handle is @shioyama and I live in Tokyo, in Japan. But don’t be fooled! I am not Japanese, in case that wasn’t obvious. I’m actually a Canadian originally from Montreal.
I work at a company called Degica based in Tokyo. We have a booth so be sure to check us out.
In the open source world, I’m the author of a few gems, the most well-known one is a gem called Mobility for managing model translations.
And I write about things like the Module Builder Pattern at my blog, dejimata.com.

Plan
This is going to be a two-part talk. In the first part, I’m going to introduce a different, more meaningful way to think about metaprogramming that will be useful for solving generic problems.
Then in the second part, we’ll solve a generic problem together in order to build what I will refer to as “generic software”.

Generalist Metaprogramming
Ok, so let’s start. “Generalist Metaprogramming”, what in the world is that?

What’s Metaprogramming?
Well, this year is Ruby’s 25th birthday, right?
And I think more than anything else, metaprogramming is an area where Ruby really stands out among programming languages. Because Ruby really embraces this concept. It underlies all these things we love, the DSLs, the human language-like syntax, all that stuff.
But we have a darn hard time defining this thing.

Defining Metaprogramming
Well ok, it’s a noun. I think we can agree on that. Unfortunately, that’s about all we can really agree on.
If “programming” is “writing code”, then the first obvious definition is “writing code that writes code”. But this doesn’t really cover everything we do with metaprogramming.
So the second definition is a “technique in which computer programs have the ability to treat programs as their data”. This one is from Wikipedia, it’s also something referred to as "reflection”.
So now we’re thinking more broadly. But if you look at the talk page on Wikipedia, you’ll see that not everybody agrees with this one either.
Another angle on metaprogramming is called “introspection”. A program is a subject, and it can find out things about other programs.
And then, at some point, we just throw up our hands and call it “a bag of tricks”. This by the way is from Metaprogramming Ruby, which by the way is a great book.

Bag of Tricks
And what are those tricks? Well, here they are. Some of you will recognize many of these. I think everyone will recognize “monkeypatching”.

The “What” View of Metaprogramming
But the thing is that, in practice, we tend to use a working definition that is much more basic. We label a subset of Ruby as “metaprogramming”, methods like eval, class_eval, define_method, etc.
And most talks about metaprogramming start there, with those methods, explaining how they work, what they do. They start with the “what” of metaprogramming.
But I don’t want to give that kind of talk today.

Metaprogramming as Fringe
And this is the reason why. It’s that for most programmers, this is what metaprogramming looks like. If they know about it at all, they just fence it off and label it as dangerous, or magical, or more likely just not useful to them.
But another part of the community, myself included — and I suspect many people here today — finds these methods absolutely essential, actually the core of Ruby.
And the reason for this divide is that most everything out there about metaprogramming with this “what” focus does not answer the obvious question: what on Earth is metaprogramming for?
And that’s the question I want to start with. To do that, I want to think about the structure of our ecosystem.

Ruby
So let’s start with a bit of fire down here, and put Ruby into the fire. Matz is feeling the heat!
So down here, this our programming language, where it is being forged out of fire and brimstone by Matz and his brave team of Ruby committers.

Applications
And then up here, we have where most of us spend our time: building applications. This is what pays our bills, this is what delivers value to our users.
And as users of the language, application developers know enough of the language to use it, but most don’t see or care much about its internals.

Libraries
Now, bridging these two worlds, we have the libraries. Or “gems”, but I’ll use the term “library” here.
Libraries fill the gaps in generic things we need - things that more than one application need - that are not supplied by the programming language.
And in Ruby in particular, these libraries are almost seamless in how they integrate with the programming language and with applications.

Metaprogramming Lives Here
And here’s the thing, right? It’s that metaprogramming overwhelmingly lives in this middle layer here, in the libraries.
Just taking Rails as an example, in Rails, it’s metaprogramming that is used to define everything you care about: attribute methods, associations, all model-specific stuff, view rendering logic, whatever.
But it’s not only ActiveRecord. Most of the widely-used gems we use heavily leverage metaprogramming to do what they do.
But applications don’t use metaprogramming much at all.
And that brings us to an obvious question, right?
Why?
Why? — Why is metaprogramming so much more prevalent in our dependencies than in our own application code?
This is such an important question. It’s telling us something very important about the nature of our programming language, and the ecosystem of components built out of it. But nobody is really asking this question, that I can see anyway.
I think part of the reason is maybe because it seems kind of obvious maybe, but I think it’s actually quite subtle. So let’s think about it a bit together now.

Generalization
Here’s another word, “generalization”. It’s the root of the second big word in the title of this talk.
Generalization is what libraries do. They generalize problems that many different applications have into generic components.
Generalization is the “formulation of general concepts from specific instances by abstracting common properties.” This is from Wikipedia again.

Abstracting Common Properties
This part, “abstracting common properties” from specific instances, is what we are going to do in the second part of this talk.

General Concepts
First, though, I want to focus on “general concepts”, and try to figure out the relation of general concepts with metaprogramming.
What’s a general concept that is relevant to everyone here?

Attribute
Well, I’m going to wager that this one is pretty relevant to almost everyone working with Ruby. The concept of “attribute”.
We want to figure out what role metaprogramming is playing in this kind of general concept, because it’s this kind of general concept that libraries implement for us.

Knockout Experiment
So to do this we’re going to take a cue from genetics. What does a geneticist do when they want to understand what a gene is doing?
Well, they knock it out. They just knock it out. And the they look to see what’s different about the mouse with the knocked out gene, compared to the mouse with the gene left in.
So we’re gong to do the same. We’ll knock out metaprogramming from the concept of “attribute”, and see what happens.

Control: Library View
So let’s start with the control. The control is the “normal” case, the one with metaprogramming.
This is the library view on the control. In each case, control and knockout, there’s a single class called “Model”, with a simple initializer that creates an empty hash to store attributes.
For the control here, we then have a class method, define_attribute, which takes an attribute name and defines getter and setter methods for that attribute. The getter just grabs the value for the key matching the method name, and the setter sets the value for the key matching the method name.

Control: Application View
And now here we’re switching to the application view, which uses this library.
In the application we define a class Talk which subclasses Model. And we
call define_attribute twice to define two attributes, title and abstract.
And then here set and get the attributes like this, set the title and get the title, and set the abstract and get the abstract.

The point I want to make here is that the abstraction, remember the abstraction of “attribute”, is transparent, or you could say it’s invisible. It’s visible when we declare it of course, but after that it’s entirely transparent when we use it.
This is what we are used to and expect, but I want to highlight that.

Knockout: Library View
Ok now for the knockout. We start with the library view like we did for the control.
In the knockout, we have no metaprogramming, so we can’t use define_method like we did in the control. We can’t define methods dynamically like that.
So instead we define two instance methods, “get_attribute” and “set_attribute”, which is the only other way to really do it. Those methods do the same thing as the methods in the control, set and get attributes as keys on the @attributes hash.

Knockout: Application View
And here is the application view for the knockout.
In this case we don’t need to declare the attributes because our implementation will let you set and get anything you like (this is not really important).
Now in this case, as I mentioned, when we want to get and set attributes, we can’t just call “title” and “abstract” as methods because the library “Model” can’t dynamically define those methods, since it has no metaprogramming to do that.
So instead we call get_attribute and set_attribute to get and set attributes (keys on the @attributes hash).

Abstraction is Visible
So I want to highlight two things here. The first is that the abstraction is now visible. Remember that our abstraction is “attribute”, and in the control case once declared, we didn’t need to think about it, we could just talk about the talk’s title and abstract.
But here, it’s in our face. Every time you access an attribute, you need to actually write the word “attribute”.

Names are Arguments
And the other thing is that names are now arguments, in this case symbols, that we pass to these methods. They are not methods now, and so we don’t send them as messages to the objects but as arguments to methods on the object.
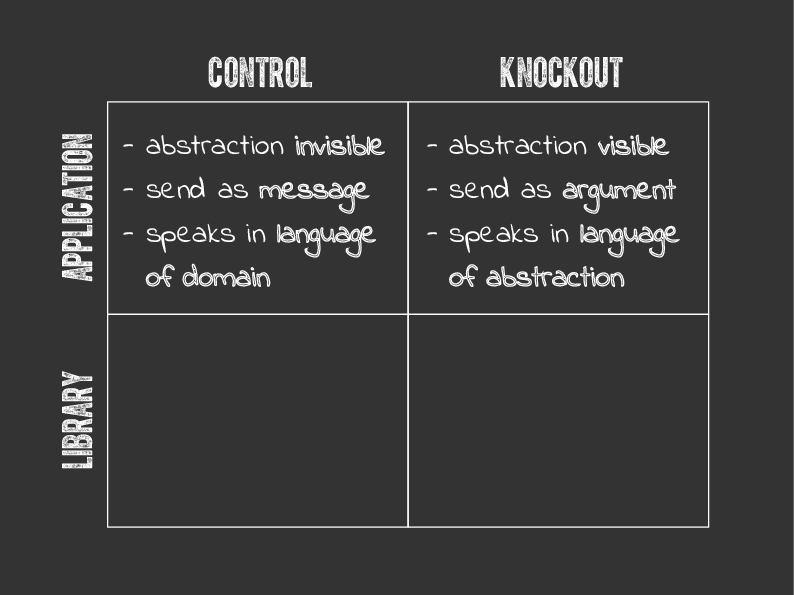
Results: Application View
Ok, so let’s tabulate the results of our experiment! We have two rows here, the first for the view from the application, the second for the view from the library. It’s really important to draw a distinction between these two.
And we have two columns, one for the control and one for the knockout. Recall that the control is with metaprogramming, and the knockout is without metaprogramming.
So from the application point of view, in the control the abstraction is transparent, or invisible, and we use the abstraction, i.e. we use attributes, by sending their names as messages to the object. And so we can say here that the library speaks in the language of the domain, i.e. you send the message “title” to the “talk” to get the title, nothing explicitly mentioning the abstraction itself there.
In the knockout, on the other hand, the abstraction is very much visible, remember we had those methods get_attribute and set_attribute. Also different: you send the attributes as values to a method, remember they were the symbols “title” and “abstract”.
So we can say here that the library speaks in the language of the abstraction. You really can’t avoid it as an application developer.
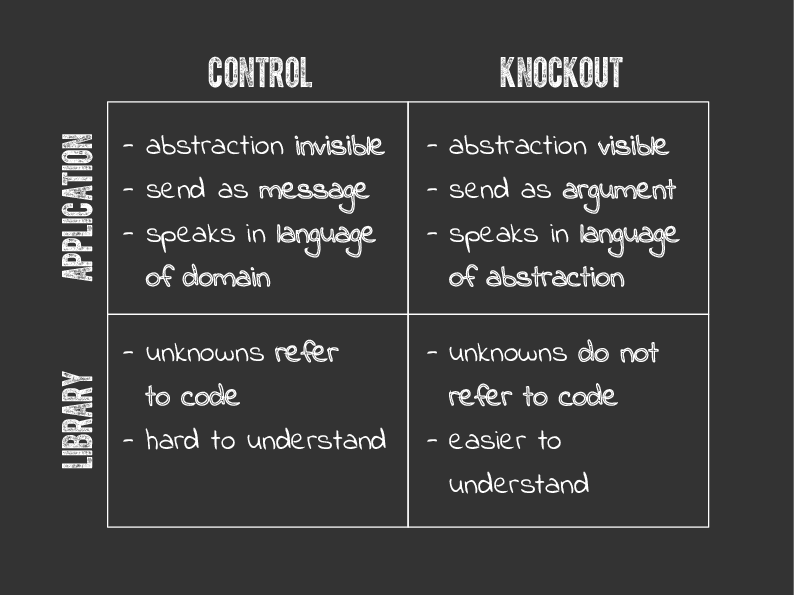
Results: Library View
Now let’s consider the library that implements this Model class. What’s going to be important here is the unknowns and what they refer to.
In the control, unknowns refer to code, to the attribute methods that we define with “define_attribute”. They are unknown because while they could be “title” and “abstract”, they could also be anything else. This makes library code hard to understand. That’s not obvious here because it’s a trivial example, but in the next section I’ll show how this can get more tricky.
In the knockout, the unknowns are the names of the attributes and their values. Attribute names are not code, they’re just keys on a hash, and that makes it easier to reason about than code with data that references code (like the control).
So if that’s the case then, why as library authors don’t we implement our code like the knockout?

Knockout ORM
Well, here’s the reason. Take the knockout example a bit further and imagine we implement an ORM like this, with associations. What would it look like?
Well, like this. We now have two general concepts here, attribute and association, but we can’t use metaprogramming for either of them, so the association abstraction is now also in your face.
So although this type of explicit abstraction is easier to handle at the library level, now it’s much more difficult to use at the application level.

Would you use this?
And so the question is: as an application developer, would you use this?
Remember that at the application level, things like the name of the talk
attributes talk and abstract are known to you.
This means that if you wanted to, you could build AR like code even without
metaprogramming by defining these methods explicitly, with def. It might
take time, but it might also be better when it comes to actually using those
methods, because now your model would speak your domain language.
So the library would be at a disadvantage compared to the specific application. This is the really key point here.

ORM with metaprogramming
And now here’s what it looks like with metaprogramming. This looks more like what we’re used to.

Metaprogramming is Translating Unknowns into Code
So here’s the takeaway: metaprogramming levels the playing field by enabling libraries to translate unknowns into code. It levels the playing field with the applications using the library.
And seeing things this way — in terms of unknowns — really reveals a lot.
Think about it for a second. What are the unknowns for the application? Well, the classic one is user input, right? Do you want to translate user input into code? Hell no!
And so this explains the divide in perceptions of metaprogramming. From the library point of view, it’s a leveler. From the application point of view it’s a freaking menace!
The other thing this new definition does is reveal some problems with our previous working definition, the “what” definition. Let’s take a look at that now.

eval(“foo”)
Here we have eval("foo"), about the simplest kind of metaprogramming you can
imagine, right?
Now, our working definition says anything with a metaprogramming method is metaprogramming, so this is metaprogramming then, right? But something feels wrong about this.
And the reason of course is that if we evaluate this, what do we get? We get
foo, a call to the method foo or to a variable by that name. And that’s not
terribly magical is it? We certainly aren’t “translating unknowns into code”.

eval(“foo#{str}”)
Ok, well what if we have a string, and we append “foo” to the string and eval that? Well, we still know the result here, which in this case would be calling foobar, whatever that is. So still not really interesting.
So how can we make this string unknown?

fooval
Well, wrap it in a method, call it fooval. Now by definition, it’s unknown,
we can’t know the value of the string here. So this is translating unknowns to
code. And it’s using eval, so in this case it lines up with both our
expectation and our definition.

attr_writer
Ok, let’s take another case, attr_writer, with an argument “foo”.
This is pretty straightforward, right? attr_writer is definitely not
metaprogramming.

attr_writer = def foo
And here’s what this evaluates to, defining a writer method foo. And that’s
not translating unknowns to code, so ok this one lines up with our
expectations.

define_writer
Ok, here’s another one. This is almost the same as the second half of the
define_attribute method I showed you earlier in the control (except that it
sets an instance variable instead of a hash value). This one uses
define_method, so in our working definition this is metaprogramming. It also
translates unknowns to code, i.e. translates name to a method, so this lines
up with our expectations too.

define_writer aliasing attr_writer
But wait a second, that stuff in the method body can be re-written to look
like this, right? It’s just aliasing attr_writer. And we said that
attr_writer is definitely not metaprogramming.
But doing things like this, wrapping attr_writer in a method, or really just
aliasing it, means that we’re translating unknowns to code. Because that’s
really what attr_writer, and attr_reader and attr_accessor, do for us.
We don’t usually think about it this way because in 99% of cases we’re passing known values to these methods, but they can be used this way too.
So this is another case where our new definition does not line up with our working definition.
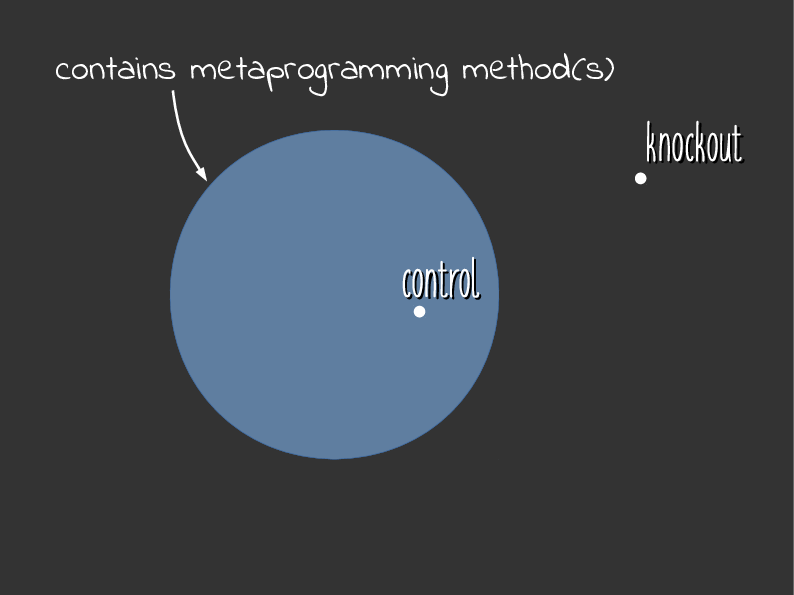
Data Points in Venn Diagram
So let’s visualize these results as Venn diagrams. Here we have our working definition, which I’ll call the “what” definition. And we have the control and the knockout here, which seem fine.
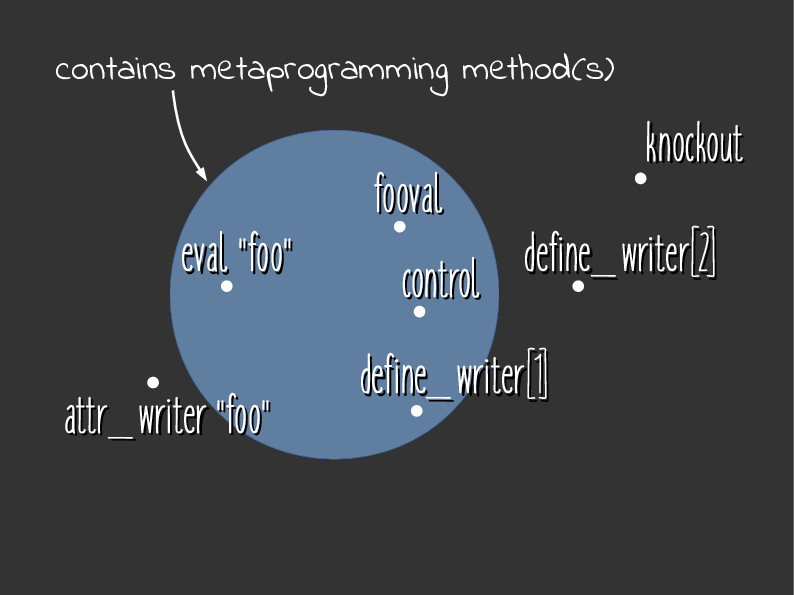
With additional data points
Now here are the other data points. Remember that eval("foo") is in this set,
but it seemed like it didn’t belong. The second define_writer, which basically
aliased to attr_writer, seemed like it did belong there, but it’s outside
the set.

New definition
So what we’re going to do is to make a new definition, which will correspond
to “translating unknowns into code”. And this definition is going to exclude
the eval("foo") one, and include the second define_writer. It’s going to do
that because it uses a definition based on what things reduce to.
eval("foo") reduces to what we call “normal programming”, i.e. a simple method
call. attr_setter wrapped in a method does not reduce to anything we’d
consider “normal programming”.
The point is that this new definition is about behaviour. It’s not about the what, it’s about the how.
So what’s normal programming then? Well, what if we invert this set on the right, and consider “normal programming” as the niche.

“Normal” Programming
So now what do we have. We have a set of methods and symbols and stuff that we consider “normal”. This is most of what you write as an application developer. Remember that this includes stuff that is normal and anything that reduces to stuff that’s normal.
In this world, code is code and data is data. Code can reference data, of course, but data never refers to code in this world. This is like the knockout example, where the attribute names did not refer to method names.

Normal Programming as Niche
And if we now zoom out and look at the big picture, this is what we have. It is “normal programming” in this picture, not "metaprogramming”, that is the niche. A very small niche in the much much larger space of computation, where we don’t draw any distinction between code and data.

Generic Software
And so where do the libraries that use metaprogramming live? Well, something like this, which I’ll refer to as “generic software”. They venture beyond the bounds of “normal programming” to make generalizations. And to do that effectively, they break that code/data barrier.
This way of understanding metaprogramming, as a means of generalizing from unknowns, is much more meaningful than any other definition out there that I have ever seen. And it really highlights what is so difficult, but also so powerful, about this concept.
To show that in more detail now, let’s look at an example of this thing I’ve referred to as “generic software”.

Building Generic Software
Ok, so “generic software”, what in the world is that, you say?

Generic Software: Definition
The term actually comes from a talk by Jeremy Evans, who is one of my heroes in Ruby. He gave a talk in 2012 about the development of Sequel, an ORM of which he’s the author, in which he said:
One of the best ways to write flexible software is to write generic software. Instead of designing a single API that completely handles a specific case, you write multiple APIs that handle smaller, more generic parts of that use case and then handling the entire case is just gluing those parts together.
And the key thing here is that the “glue”, in many cases and in particular in cases where the software needs to speak the domain language, will be metaprogramming, by the definition we came to in the last section.
So I want to explore this idea of “generic software”, but we need a general concept. We’ve already used “attribute”, so next I’m going to use…

Equality
Equality! Can’t get much more general than that, right?
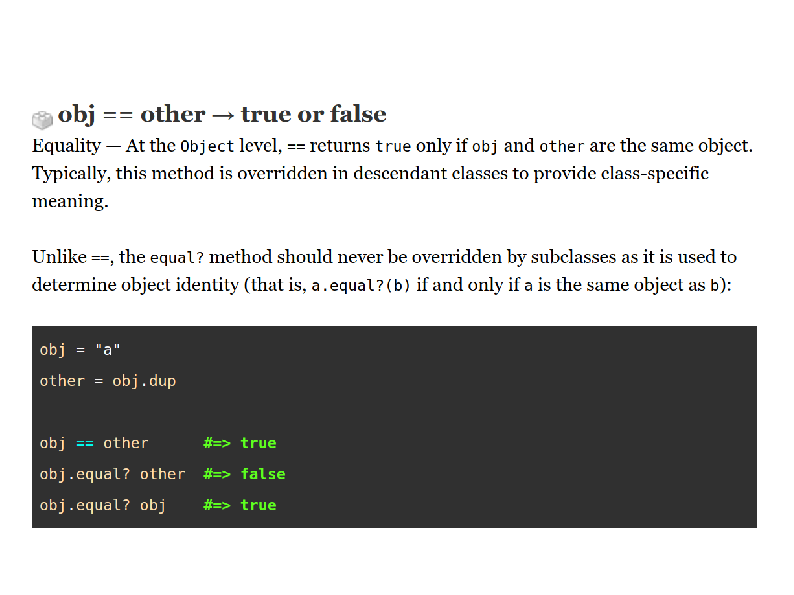
Double Equals Equality
So there are a few methods for equality in Ruby, we’re going to be focusing here on “double-equals” equality. That’s the kind of equality that compares object content, not object identity.
So e.g., two strings which both have the characters f o o are
double-equal equals even if they are different actual objects.
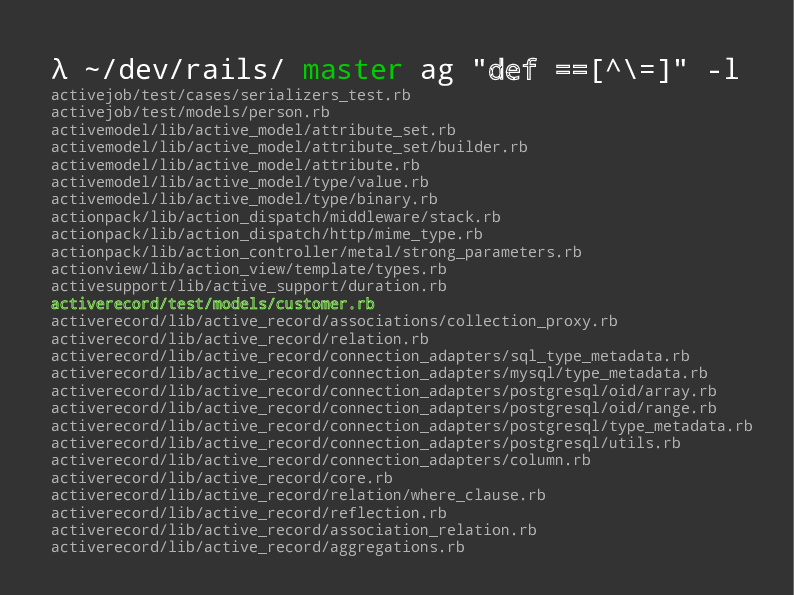
Finding a Use Case
Ok but we need some specific examples, like in the definition of generalization we saw earlier. So let’s go where everyone goes for examples, to Rails! And grep for it.
And we actually find a bunch of files that mention this type of equality.
To start we’ll use some classes defined in tests, just because they’ll be a bit easier to visualize, but we’ll come back afterward and apply it to models in other files here.

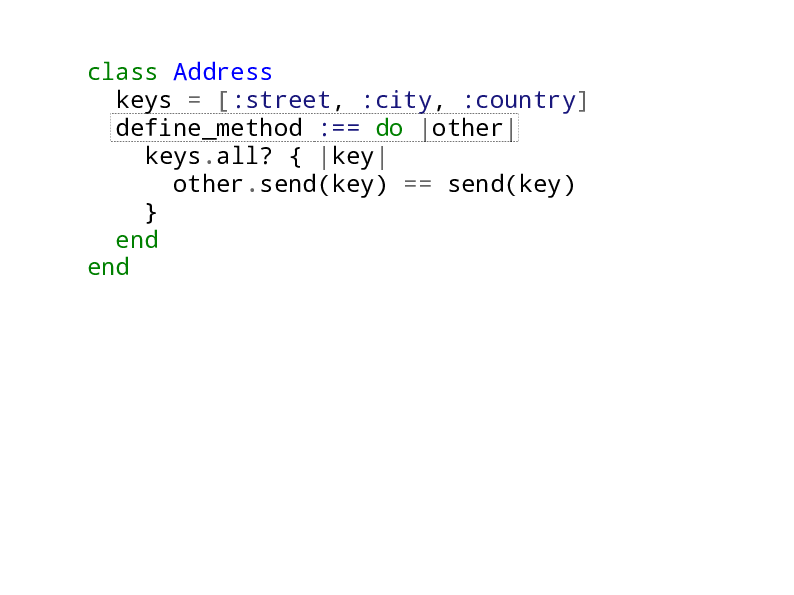
Address
So here’s the Address class, just has a few attr_readers for the attributes
street, city and country, and an equality method that compares two addresses
based on the values of those attributes.

Address
And we have this GpsLocation class, which is very similar. Here the methods
are not defined using attr_reader, but that doesn’t really matter for us. We
just care that there is a double-equals method and that it’s defined in terms
of a list of methods.

Address + GpsLocation (1)
Ok, so let’s line them up together. We notice a small difference, which is
that Address has this other.is_a?(self.class) and GpsLocation does not, but
it’s not terribly important and could easily be added back, so we’ll just
remove that one to simplify things. It won’t change anything about what I’m
going to show you.

Address + GpsLocation (2)
Ok so now we need to extract what is common about these two methods. We’ll start by noticing that calling a method in Ruby is exactly the same thing as calling send with the method name as an argument. So let’s do that instead.
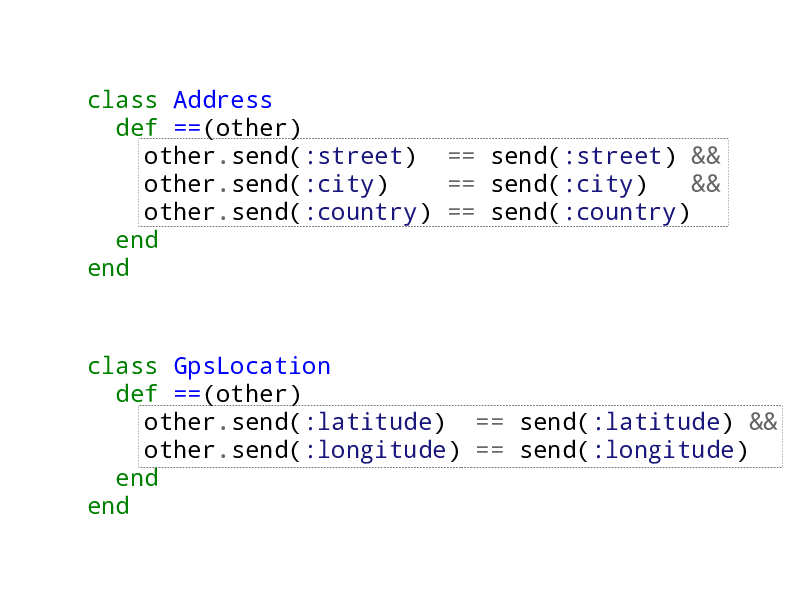
Extract with send
So you can see, in the first step here we’ve extracted something that was code
- the method calls - to something that is data, the method names we’re passing
to send. That’s important.

Extract Array
Now we’re going to refactor the sets of equality predicates using the
enumerable method all?. This method takes a block and passes each element to
the block, then takes the AND of the results.
In this case, the block will be the comparison of sending the attribute name to self and to the other object, and this will give us the same result as before.
(I’ve dropped GpsLocation here by the way since everything we’re doing now
will be exactly the same for both classes, except the names will be
different.)

Abstraction: key
Notice now that we have the first indication of our abstraction, the argument to the block here, “key”. This is an abstraction for the method names that define equality on each of these classes.

Keys
Ok now we’re going to name the array of keys as a variable “keys” and pull it out. Again, nothing has changed here, we’re just moving stuff around.

Replace def with define_method
Ok, so here’s an important step. We’re replacing def with define_method.
Remember that in our original working definition, this would mean that this was now metaprogramming. But in fact, nothing has changed, not yet anyway.
With our new definition, this is not metaprogramming because we are not translating any unknowns into code. We’re only translating knowns into code, the array of keys in each case. And we know what those keys are.
So you can see that our new definition is giving us more useful information about what is going on.
Hoist Keys
Ok, now we “hoist” the keys out of the define_method block. We can do that
because blocks have an open scope, so what’s in the block can see the keys
array, even if it’s outside of the block itself. (This is now a closure, if
that says anything to you.)

Method Arguments
Now I want to look at these things differently. These keys we’re going to
think of as arguments to a method. In GpsLocation the keys would be latitude
and longitude, but for Address they are street, city, country.

Method Body
And now look at this code here. This is now independent of the keys, i.e. independent of what makes Address and GpsLocation different. So we can now extract it.
But how? By wrapping it in a method, like we saw earlier.

equalize
So we create a class method equalize, which takes arguments keys. The splat
just means we can pass arguments and they will be captured in an array.
The code inside equalize is exactly the same as what we had in the last slide. But now since it’s in a method, we need to call it, which we do, just below. We call it with street, city, country.
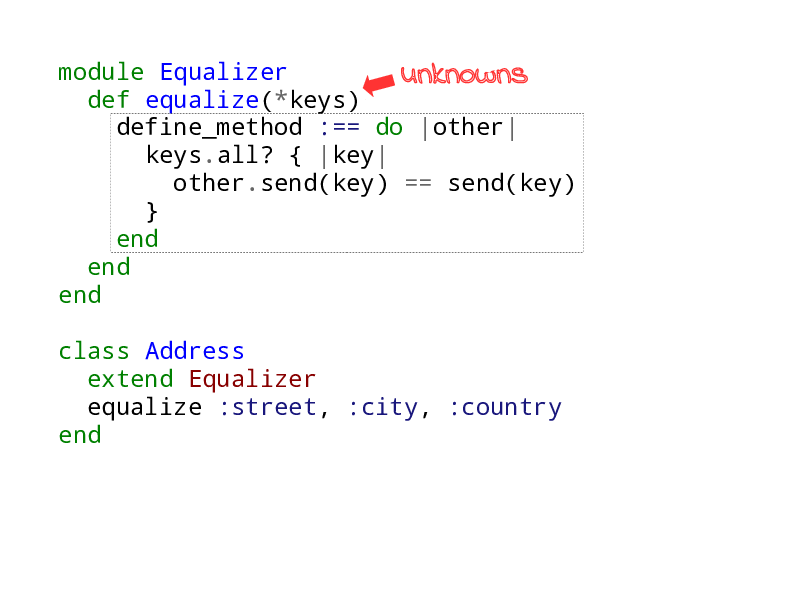
Equalizer
Ok, and so now we can finally extract the module that will be our gem code. We
extract that class method into a module, Equalizer, and we extend Address with
it and call equalize with the keys.
That module is now our gem. And notice our unknowns? They are the keys to the equalize method.

require “equalizer”
And now that it’s a gem, a library, we can just require it, like this.
And now things are starting to look pretty nice and clean, right? The Address class is simpler than it was originally, but it’s very clear what is defining equality on each of them.
This is the sign of a good abstraction: it captures the essence of a general concept.
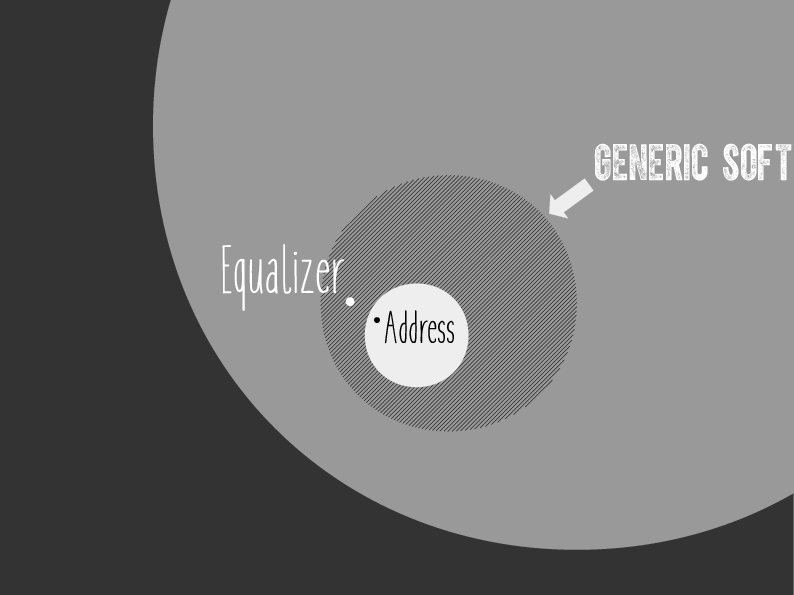
Equalizer in Big Picture
And now in that diagram I showed you earlier, here is where we are. We’ve
extracted the generic component from Address (and GpsLocation would be the
same), and this generic component, this generic software, now lives in this
larger space outside of what we call “normal programming”.
Equalizer has data that refers to code, the keys that refer to method names
defining equality.

Refactor other Classes with Equalizer
And now that we’ve done this, we can apply Equalizer to other classes. Here we
have GpsLocation, but also a bunch of other classes from that list I showed
you earlier. You can see we’ve hit on a very general pattern.

Equalizer Again
So here’s our Equalizer module again. This is a very compact little module,
but there are a few important things going on.
Look at how define_method captures the keys in a block. Note that you couldn’t
do this without define_method, because def has a closed scope, it doesn’t
accept a block. Likewise, we could not build this method without calling the
equalizer methods using send, because the keys here are unknown values.
Ruby provides methods like define_method and send for a very specific purpose,
but that purpose is not clear unless you are solving a generic problem like
this. Of course you could also use eval – eval is the “universal solvent”
that dissolves anything, but it is an ultimate fallback and rarely used in
practice.
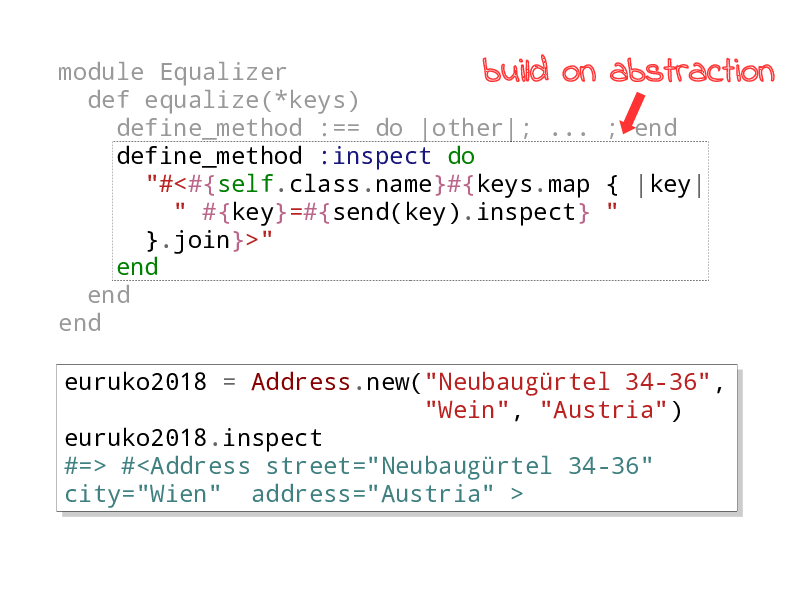
Add inspect method
And the beauty of this is that once we have these keys, and these methods for dynamically defining methods and sending messages that Ruby provides, we can take this further.
We can observe that whatever defines equality basically defines identity. So we can use that fact to define an inspect method which shows the values of the key methods.
And you can see that this is useful in the example here.
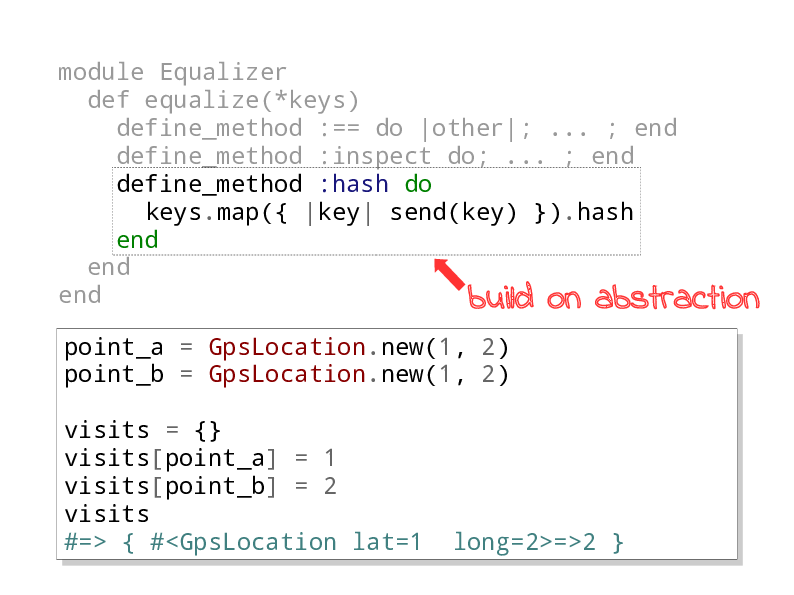
Add hash method
And we can go further building on the abstraction, and add a hash method. The
hash method is used to determine if two keys on a hash are the same or not, so
by defining this method we allow instances of classes that extend Equalizer
to be used as hash keys.
Here’s an example where GpsLocations are used as a hash of number of times a
given location has been visited. We have two points, but they are the same
latitude/longitude, so only one key in the hash is updated.
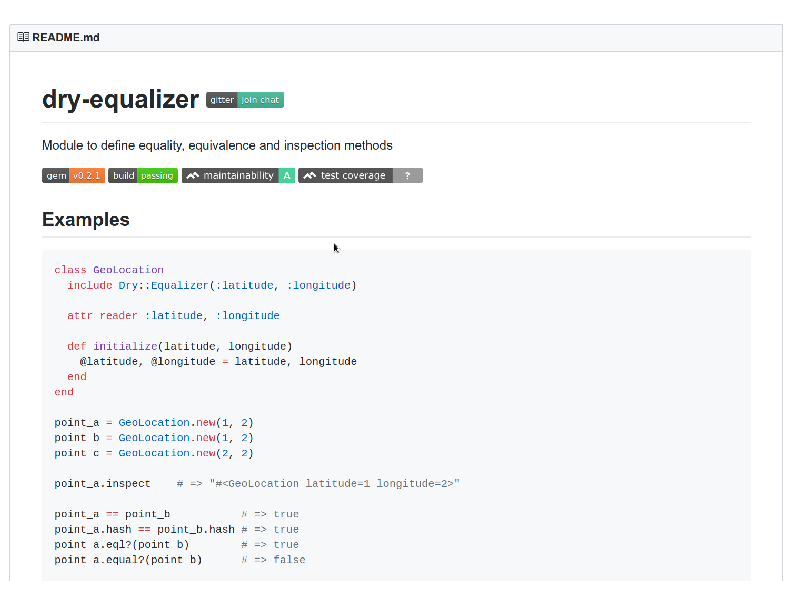
Dry Equalizer
Now, if all this seems useful to you, I have some good news! There’s a gem for it, called Dry Equalizer.
It’s one of the dry-rb gems, which are fantastic examples of generic software by the way. It’s a very very small gem, just a bit more than what we have here, done a little bit more cleverly, but basically the same idea.
DryEqualizer in dry-rb gem network
DryEqualizer may seem quite simple, but it plays a very important role in the network of dry-rb gems, which are being more and more heavily used in many applications. dry-equalizer is actually right at the core of this network, because it is so simple and so generic.

Being a Generalist (1)
Ok, so just before I close here, I want to come back to the title of this talk.
The title was “Metaprogramming for Generalists”, not “Metaprogramming and Generalization”, or “Metaprogramming and Generic Software”.
And there’s a reason for that.
“Generalist” usually means someone who has broad knowledge across different fields, and the ability to bridge ideas from various different areas.
And you can do that by jumping from one field to the other and learning high-level things about them, like this.

Being a Generalist (2)
But there’s another way to think of the “generalist”, as someone who digs deep down, to the general concepts that underlie all sorts of different problems. Concepts like “attribute” and “equality”.
Once you find these core concepts, and capture them in an abstraction, like the Equalizer module you saw, then you really grasp something very fundamental about a whole class of problems at once.
And then you can build on the abstraction, and everything you build will broaden the reach of the software.

Being a Generalist (3)
And as a community, we really need more of you to do this, to delve down to this world.
Solving generic problems, and solving them well, benefits everyone at all levels, by making every specific instance of that general problem easier to solve.
This is the metaprogramming magic that makes our ecosystem so powerful. It’s what makes Ruby the language it is.
